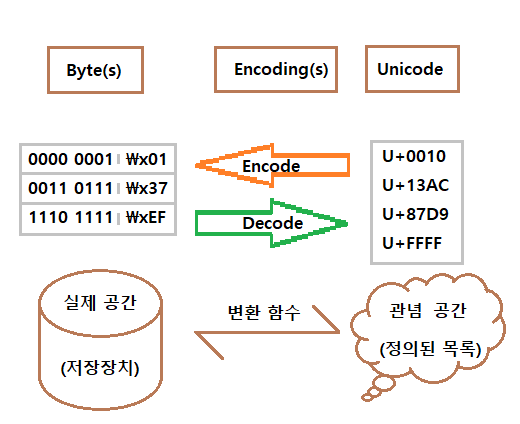
ASCII는, HEX 0x00 ~ 0x7F (== DEC 0 ~ 127) 범위에서만 정의되었다. 그런데 바이트 0x80~0xFF (== DEC 128 ~ 255)를 코덱에 따라 번역하라고 하니, 오류가 나는 것이다. 이 오류가 뜨면, 다른 코덱 쓰면 해결된다. 한국어면 utf-8, cp949, utf-16 순으로 해보고, 영어권이면 적절한 다른 코덱들 쓰면 된다. 오류나는 바이트 값들은 접은글에 넣어뒀다. 더보기 0x80 0x81 0x82 0x83 0x84 0x85 0x86 0x87 0x88 0x89 0x8A 0x8B 0x8C 0x8D 0x8E 0x8F 0x90 0x91 0x92 0x93 0x94 0x95 0x96 0x97 0x98 0x99 0x9A 0x9B 0x9C 0x9D 0x9E 0x9F 0xA0 ..